在當今數據驅動的時代,企業正以前所未有的速度生成和消費數據。構建一個高效、可擴展且穩定的大數據處理系統,已成為企業提升競爭力、實現智能決策的核心基礎。一個設計精良的大數據架構圖,不僅是技術實現的藍圖,更是連接業務需求與技術能力的橋梁。本文將系統闡述如何設計一套高效的大數據處理系統架構,并深入探討其中的數據處理服務。
一、 大數據系統架構的核心理念與分層設計
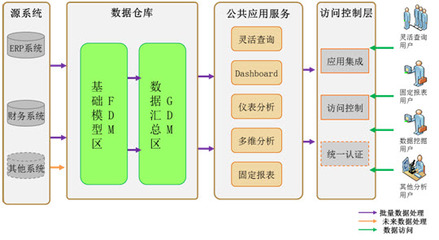
一個現代化的大數據處理系統通常采用分層架構,以實現職責分離、靈活擴展和高效管理。典型的分層包括:
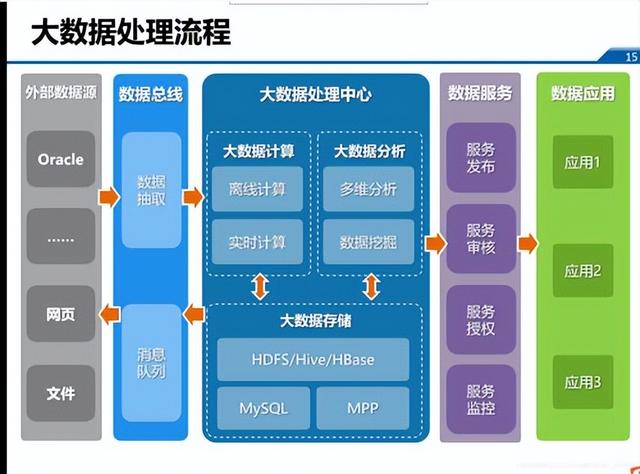
- 數據源層:系統數據的起點,包括關系型數據庫、NoSQL數據庫、日志文件、IoT設備數據流、第三方API等。此層的關鍵是確保數據的可接入性與多樣性支持。
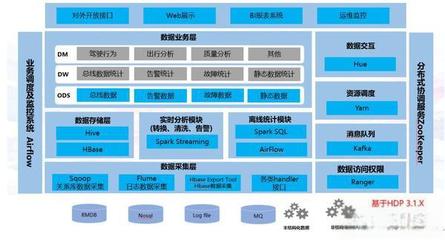
- 數據采集與集成層:負責從各種異構數據源實時或批量地抽取、轉換和加載數據。核心組件包括Apache Kafka(用于高吞吐量的實時數據流)、Apache Flume(日志收集)、Sqoop(關系型數據庫與Hadoop間數據傳輸)及ETL/ELT工具。設計要點在于保證數據的低延遲、高可靠性與順序性。
- 數據存儲層:作為系統的“數據湖”或“數據倉庫”,存儲海量原始數據與加工后的數據。根據數據特性和訪問模式,可選擇不同的存儲方案:
- 分布式文件系統:如HDFS、S3,用于存儲原始、非結構化的海量數據。
- NoSQL數據庫:如HBase、Cassandra,用于快速隨機讀寫和存儲半結構化數據。
- 數據倉庫:如Hive、ClickHouse、Snowflake,用于存儲結構化的、面向分析的歷史數據,支持SQL查詢。
- 實時存儲:如Redis、Druid,為實時應用提供低延遲的數據訪問。
- 數據處理與計算層:這是系統的“大腦”,負責數據的核心價值挖掘。根據時效性可分為:
- 批處理:處理歷史全量數據,通常由Apache Spark、MapReduce、Hive等框架完成,適用于報表生成、離線分析等場景。
- 流處理:處理無界數據流,實現實時或近實時的分析,常用框架有Apache Flink、Spark Streaming、Kafka Streams。
- 交互式查詢:提供亞秒級響應的即席查詢,如Presto、Impala。
- 數據服務與API層:將處理后的數據以安全、標準化的方式暴露給下游應用和用戶。這包括RESTful API、GraphQL接口、數據可視化接口等,是數據價值輸出的最終出口。
- 管理與監控層:貫穿所有層次的支撐體系,包括資源管理(YARN、Kubernetes)、作業調度(Airflow、DolphinScheduler)、元數據管理(Atlas)、數據血緣、安全(Kerberos、Ranger)以及全面的指標監控與告警(Prometheus、Grafana)。
二、 數據處理服務:架構中的“動力引擎”
數據處理服務并非一個孤立的組件,而是一套貫穿于計算層和服務層的、可復用的能力集合。其核心目標是將原始數據轉化為可直接用于分析、應用或決策的“信息產品”。
- 服務化設計原則:
- 模塊化與解耦:將數據清洗、轉換、聚合、特征工程等任務封裝成獨立的微服務或函數,通過標準接口(如消息隊列、RPC)調用,提高系統的可維護性和擴展性。
- 彈性與可擴展性:服務應能根據負載自動擴縮容,利用云原生或容器化技術(如Docker+K8s)實現資源的高效利用。
- 容錯與可靠性:設計重試機制、死信隊列、檢查點(Checkpointing)等,確保數據處理任務在失敗時能夠恢復,保證數據一致性。
- 關鍵服務類型:
- 數據質量服務:自動檢測數據的完整性、準確性、一致性和時效性,并生成質量報告或自動觸發修復流程。
- 實時特征計算服務:基于流處理框架,實時計算用戶畫像、業務指標等,為推薦系統、風控系統提供即時輸入。
- 模型預測服務:將訓練好的機器學習模型部署為在線API,供業務系統調用,實現實時智能決策。
- 統一查詢服務:對內外部用戶提供一個屏蔽底層存儲和計算復雜性的統一SQL或API入口,實現跨數據源的聯邦查詢。
三、 架構圖設計實踐與演進
在設計具體架構圖時,需遵循以下步驟:
- 明確業務目標與需求:是追求實時風控、個性化推薦,還是高效的離線報表?不同的目標決定了架構的側重點(流處理優先還是批處理優先)。
- 選擇合適的技術組件:基于團隊技術棧、社區活躍度、云服務商支持等因素,為每一層選擇成熟穩定的組件,并考慮組件間的兼容性與集成成本。
- 繪制邏輯架構圖與物理部署圖:邏輯圖展示數據流與組件關系;物理圖明確服務器、集群、網絡及云服務的具體配置,這是成本評估和運維的基礎。
- 持續迭代與優化:大數據架構不是一成不變的。隨著業務發展和技術進步,架構需要持續演進,例如向流批一體(如Flink)、數據湖倉一體(Lakehouse)等更先進的范式遷移。
###
設計一個高效的大數據架構,本質上是在復雜性、性能、成本與敏捷性之間尋求最佳平衡。一幅清晰的大數據架構圖,能夠幫助團隊統一認知、有效協作。而將數據處理能力服務化,則是提升系統靈活性、加速數據價值交付的關鍵。一個成功的大數據處理系統,不僅要技術先進,更要緊密貼合業務,能夠穩定、高效地驅動業務增長與創新。